
原始论文:Slope One Predictors for Online Rating-Based Collaborative Filtering
Slope One: 基于在线评分的协同过滤算法
摘要
基于评级的协同过滤是预测的程序,即根据用户对其他物品的评分来预测用户会如何评分当前给定的物品。我们提出了三个形式为f(x)= x + b的关于slop one机制的预测模型,预先计算出用户共同评分过的一个物品和另一个物品的评分之间的平均差异。slop one算法是易于实现的,查询效率高,相当准确,同时它们支持在线查询和动态更新,这使它们成为现实系统的良好候选者。建议将基本的SLOPE ONE方案作为协同过滤方案的新参考。通过考虑将用户喜欢和不喜欢的物品从全集中分出来,我们通过较慢的基于记忆的方式实现了结果超过基准EveryMovie和Movielens数据集,同时更好地满足了它对协同过滤应用的需求。
关键词:协同过滤,推荐工具,电子商务,数据挖掘,知识发现
1 介绍
基于在线评级的协同过滤CF查询由来自单个用户的(物品,评分)对的数组组成。对该查询的响应是一个由用户还没有评分的物品集合构成的预测数组对(物品,评分)。我们旨在提供强大的CF机制,包括:
- 易于实现和维持:所有的或者那个数据应该可以有跑一版的工程师很轻松地解读,并且算法应该很容易地被实现和测试;
- 即时可更新:新评分的添加应该可以立即改变所有预测;
- 查询时效性:查询应该很快,可能以储存为代价;
- 对第一个访客的期望很少:很少评分的用户应该也能收到有效的推荐;
- 准确无误:算法机制应争先用最准确的方案,除非准确性收益微薄的话,并不总是值得在简单性或可扩展性方面做出重大牺牲。
我们在本文中的目标不是比较准确性各种CF算法,而是演示Slope One计划同时满足所有五个目标。尽管我们的计划很简单,它们具有可更新性,计算高效性和可扩展性,它们的准确性与放弃某些其他优点的方案相当。
我们的Slope One算法通过用户的项目之间的“流行度差异”以直观的原理起作用。以成对的方式,我们确定一个物品比另一个更好多少。衡量这种差异的一种方法只是简单地这两个项目的平均评分相减。反过来,给定用户对一个物品的评分后,这种差异可以用来预测另一个用户对其中一个物品的评分。考虑两个用户A和B,两个物品I和J以及图1。用户A给予物品I评分为1,而用户B给予它一个评分为2,而用户A给予物品J评级为1.5。我们观察物品J的评分大于物品I的1.5-1 = 0.5分,因此我们可以预测用户B将给出物品J的评分为:2 + 0.5 = 2.5。我们将用户B称为预测用户和项目J是预测项目。许多这样的差异存在于每个未知评分的训练集,我们取这些差异的平均值。slop one机制在这里呈现了我们选择三种相关的差异方式达到单一预测。
本文的主要贡献是提出slop one协同过滤预测算法并证明它们具有竞争力,和基于记忆的方案具有几乎相同的准确度,同时更适合CF任务。
2 相关工作
2.1 基于记忆和基于模型的机制
基于记忆的协同过滤算法使用用户间的相似度来进行预测,最经典的就是通过加权平均。
所选择的相似性度量决定了预测准确性,并且已经研究了众多替代方案。基于存储器的CF的一些潜在缺点包括可扩展性和对数据稀疏性的敏感性。一般来说,依赖于跨用户相似性的方案在快速在线查询的时候进行预先是不可能的。另一个关键问题是基于记忆的方案必须计算用户之间的相似性,并且衡量标准通常需要一些最小用户数(比如说,至少有100个用户)输入了一些最小个数的评分(比如说至少是20个评分)包括当前用户。我们会将我们的算法和着名的基于内存的方案进行对比,皮尔逊算法。
CF有许多基于模型的方法。一些基于线性代数(SVD,PCA或Eigenvectors);或者直接借用来自人工智能的技术,如贝叶斯方法,隐含分类,和神经网络,或聚类。与基于内存的方案相比,基于模型CF算法通常在查询时更快但是可能有昂贵的学习或更新阶段。基于模型方案可以优于基于存储器的方案,当查询速度至关重要时。
我们会将我们的预测算法与在下面的代数文献中描述的某些类型的预测方法进行比较。因此,我们的预测模型的形式为$f(x)= x + b$,因此名称定为“slope one”,其中b是常数,x是变量代表评分值。对于任何一对物品,我们试图找到从其他物品的评分来预测此物品评分的最佳函数f。这个函数可能对于每个物品对都不一样。 CF机制将加权预测模型产生的诸多预测。在[14]中,作者考虑了成对项目之间的相关性然后导出用户评分的加权平均值作为预测。在他们算法的简单版本中,他们的预测模型形式为$f(x)=x$。在他们的以回归为基础的算法版本中,他们的预测模型形式是$f(x)= ax + b$。在[17]中,作者也采用了预测因子形式$f(x)= ax + b$。基于这两篇论文一个自然延伸的研究,将会考虑这样的预测模型的形式:$f(x)=ax^2 + bx +c$。相反,在这篇文章,我们使用简单的预测模型形式$f(x)= ax + b$。我们也是用最普通的加权方法。可在[14]看到的是,甚至他们的基于回归方程$f(x)= ax + b$的算法依然不能够获得相对于基于记忆算法较大的改进。因此可以得到一个重要的结论就是基于$f(x)= ax + b$形式的预测模型可以与基于记忆的算法机制进行竞争。
3 CF 算法
我们提出了三种新的CF方案,并将我们剔除的机制和之前提到的四中算法进行对比:PER USER AVERAGE, BIAS FROM MEAN, ADJUSTED COSINE ITEMBASED,这是一个基于模型的方案,以及PEARSON机制是代表基于记忆的方案。
3.1 符号
我们在算法描述中使用以下符号。来自给定用户的评分,称为评估,表示为一个不完整的数组u,其中$u_i$是该用户给出了物品i的评分。又被用户u评分过的所有物品组成的子集表示成S(u)。训练集中所有评估的集合表示成$\chi$。集合S中的元素个数是card(S)。用户u所有评分的平均评分为$\bar u$。集合$S_i(\chi)$是所有评估$u \in \chi$中包含物品$i(i \in S(u))$组成的集合。给定两个评估u,v,我们定义标量积$(u,v) = \sum_{i \in S(u) \cap S(v)} u_i v_i$。预测,我们写成P(u),表示每个分量都是对应一个物品预测结果的向量:预测隐含地依赖于训练集$\chi$。
3.2 基准方案
一个最基础的预测算法就是PER USER AVERAGE方案,给定的等式是$P(u)=\bar u$。也就是说,我们预测用户将根据该用户的平均评分对所有内容进行评级。
另一个简单的方案称为BIAS FROM MEAN(有时候也称为NON PERSONALIZED)。等式给定为:
也就是说,这个预测是基于用户平均评分再加上训练集中所有用户对该物品的评分与其用户的评分平均值的平均偏差。我们也比较了基于物品的算法并且结果显示效果最好[14],其中给出了使用以下调整后的余弦相似性度量,当给定两个物品i和j:
最终预测是由这些度量加权求和得到的:
其中回归系数$\alpha_{i,j},\beta_{i,j}$是由在i和j固定的条件下最小化$\sum_{u \in S_{i,j}(u)}(\alpha_{i,j} u_j \beta_{i,j} - u_i)^2$
3.3 参考PEARSON方案
因为我们希望证明我们的方案相比于基于记忆的方案的预测能力更具有可比性,但由于意识到这一类的方案有许多种,所以我们选择的是实现其中一个算法作为这类方案的代表。其中最受欢迎和准确的记忆基础算法是PEARSON方案。需要的$\chi$中所有用户的加权总和形式:
其中$\gamma$是Pearson相关性计算得到的相似性度量:
基于[2,8],我们设定:
其中$\rho = 2.5$,它是样本的权重。此值降低了数据中的噪声:如果相关性是特别高的话,例如0.9,那么经过这层变化后依然可以保持高相关性$(0.9^{2.5} \cong 0.8)$,而当相关性较低的时候例如0.1,那么经过变化后会变得很小$(0.1^{2.5} \cong 0.003)$。论文[2]已经证明了相比于已经存在一些方案,结合样例加权的皮尔逊被证明了在CF算法中更具合理性和准确性。
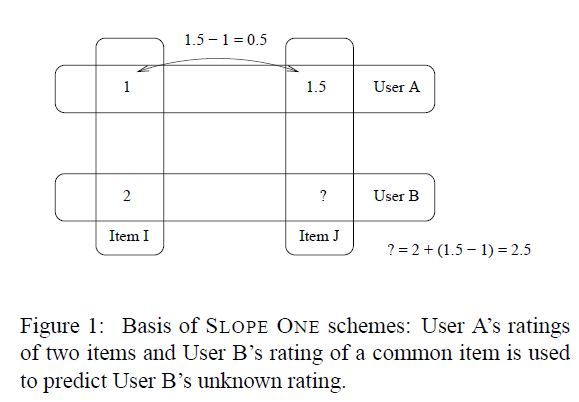
3.4 SLOPE ONE算法
slope one算法不仅考虑了评分过当前物品的其他用户的信息,同时还考虑了被当前用户评分过的其他物品的信息。然而,这些算法也是如此依赖于既不属于用户数组也不属于物品数据的数据点(例如,用户A对图1中项目I的评级),但是这些数据仍然是评分预测的重要信息。该方法的大部分优势来自数据没有考虑到的因素。具体来说,只有那些与预测用户评分了一些共同物品并且只有与预测用户拥有的物品评分的用户评分进入slop one的评分预测方案。
正式的,给定两个评分数组$v_i$和$w_i$,其中$i = 1,…,n$,我们寻找形式为$f(x)=x + b$的最好的预测模型来基于v通过最小化$\sum_i (v_i + b - w_i)^2$预测w。将上式对b进行求导并将导数设置为零,我们可以得到$b = \frac{\sum_i w_i - v_i}{n}$。换句话说,常数b必须选自两个数组间的平均差异。这就可以推导出一下的算法。
给定训练集$\chi$,以及两个物品j和i以及一些用户对它们的评分$u_j$和$u_i$(其中$u \in S_{j,i}(\chi)$),我们考虑物品i和j之间的平均偏差为:
注意任何不包含对i或j评分$u_i,u_j$的用户评论都不包含在上述的求和中。对称矩阵$dev_{j,i}$可以在新数据尽来的时候快速地计算和更新。
固定$u_i$的时候,$dev_{j,i} + u_i$即为$u_j$的预测值,一个合理的预测应该对这些预测值进行平均:
其中$R_j = {i|i \in S(u), i \neq j, card(S_{j,i}(\chi)) > 0}$是所有相关的物品集合。有一个近似的方案可以简化预测的计算。对于一个足够密集的数据集,即任意一对物品都有评分数据,也就是,对于几乎所有的i和j都有$card(S_{j,i}(\chi)) > 0$, 大多数时候,当$j \in S(u)$的时候,对于$ j \notin S(u) \ and \ R_j = S(u) -{j}$都有$R_j = S(u)$。由于对于大多数的j有$\bar u = \sum_{i \in S(u)} \frac{u_i}{card(S(u))} \simeq \sum_{i \in R_j} \frac{u_i}{card(R_j}$,我们可以对slop one的预测公式简化成:
有趣的是注意到我们实现的SLOPE ONE算法是不依赖于用户是如何评论每个单个物品的,仅仅依赖用户的平均评分以及那些物品被当前用户评分过。
3.5 加权SLOPE ONE算法
虽然加权相对于不常见的评级模式来说是有利于经常出现的评级模式的,我们现在将会考虑另一种特别相关的评级模式。我们通过将预测分为两部分来实现这一目标。使用WEIGHTED SLOPE ONE算法,我们得到一个用户喜欢的物品预测和另一个使用用户不喜欢物品的预测。
给定一个评分范围,例如0到10,将此范围的中间值5作为阈值看上去是比较合理的,即物品评分大于5认为用户是喜欢的,相反小于5则是不喜欢的。这个方法对于用户评分是均匀分布的时候是特别有效果的。然而,每部电影超过70%的平方根都是大于这个中位数的。因为我们想要支持所有类型的用户,包括平衡,乐观,悲观和双峰用户,我们将用户的平均值应用为用户喜欢和不喜欢的物品之间的阈值。例如,乐观的用户,就是那些评价的每一个物品都是喜欢的用户,那么评分低于其平均评分的都被认为不喜欢这些物品。该阈值确保了这一点我们的算法对于每个用户都有一定数量的喜欢和不喜欢的物品。
再次参考图1,像往常一样,我们对用户B对J评分的预测是基于其他用户对J和物品I评分的差(例如用户A)这些用户是同时评论过物品I和J的。BI-POLAR SLOPE ONE算法进一步限制了这组评分这是预测性的。首先是物品,只有两个都喜欢的物品评分的或两个都不喜欢的物品的偏差才会被考虑在内。再次对于用户,对同时评论过物品I和J的用户的偏差以及展现出喜欢或者不喜欢物品I的用户会被用来预测物品J。
将每个用户分成用户喜欢和用户不喜欢有效地使用户数增加一倍。显然,但请注意两极限制刚刚概述了在计算中减少预测评级的总数预测。虽然准确度有所提高对于这种减少的看法可能看似违反了直觉即数据稀疏性始终是一个问题,未能过滤掉那些无关紧要可能证明更有问题的评论。最重要的是,BI-POLAR SLOPE ONE方案无法预测出用户A喜欢物品K而用户B不喜欢物品K这一事实。
正式的,我们将每一个u的评论分成两个评论物品的集合:$S^{like}(u) = { i \in S(u)|u_i > \bar u}$和$S^{dislike}(u) = { i \in S(u)|u_i <\bar u}$。对于每个物品对i和j,将所有相关评论组成的集合$\chi$分成$S_{ij}^{like}= { u \in \chi|i,j \in S_{like}(u)}$和$S_{i,j}^{dislike} = {u \in \chi| i,j \in S^{dislike}(u)}$。使用这两个集合,我们计算下面的喜欢物品偏差矩阵,类似的不喜欢的物品偏差矩阵就是$dev_{j,i}^{dislike}$:
物品j的评分预测是基于物品i的评分$p_{j,i}^{like} = dev_{j,i}^{like} + u_i$或者$p_{j,i}^{dislike} = dev_{j,i}^{dislike} + u_i$依赖于i分别属于$S^{like}(u)$还是$S^{dislike}(u)$。
最终BI-POLAR SLOPE ONE算法可有下式给出:
其中权重$c_{j,i}^{like} = card(S_{j,i}^{like})$以及$c_{j,i}^{dislike} = card(S_{j,i}^{dislike})$是类似于一个加权SLOPE ONE算法。
4 实验结果
一个给定的CF算法的有效性是可以被精确测算的。为此,我们使用了All But One Mean Average Error(MAE)[2]。在计算MAE时,我们先后从所有评估中每一次隐藏一个评分剩下的作为测试集,同时预测这个被隐藏的评分,计算我们在预测中犯的错误平均值。给定一个预测模型P以及一个用户的评论u,那么通过评论集合$\chi’$可以得到P的误差率可由下式给到:
其中$u^{(i)}$是评论集合u,并且其中隐藏了用户对第i个物品的评分。
我们在由Compaq Research提供EveryMovie数据集以及来自明尼苏达州大学的Grouplens研究小组的Movielens数据上测试我们的方案。数据来自电影评级网站,其中EachMovie评分范围从0.0到1.0,增量为0.2,Movielens的每个电影评分是从1到5的,且增量为1。根据[8,11],我们使用了足够的评论数据来得到总数为50000个评分数据作为训练集$(\chi)$,和另外一组总数至少100000个评分数据作为测试集$(\chi’)$。当预测结果对给定数据集的评级超出允许范围时,它们会相应地进行更正:一个电影的预测值为1.2,若是范围从0到1则将其看作是预测结果为1。因为Movielens的电影评分范围比MovieMns的每个电影大4倍,那么除以4使结果直接可比。
不同算法的测试结果汇总在了表1中,它们都是基于同一个数据集以及相同的误差度量得到的。不同的子结果都列在了表格的后面。
| Scheme | EachMovie | Movielens |
|---|---|---|
| BI-POLAR SLOPE ONE | 0.194 | 0.188 |
| WEIGHTED SLOPE ONE | 0.198 | 0.188 |
| SLOPE ONE | 0.200 | 0.188 |
| BIAS FROM MEAN | 0.203 | 0.191 |
| ADJUSTED COSINE ITEM-BASED | 0.209 | 0.198 |
| PER USER AVERAGE | 0.231 | 0.208 |
| PEARSON | 0.194 | 0.190 |
Table 1: All Schemes Compared: All But One Mean Average Error Rates for the EachMovie and Movielens data sets, lower is better.
考虑不同基准方案的测试结果。如期所致,我们发现在本文3.2部分描述的3个基准方案中BIAS FROM MEAN算法表现的最好。然而有趣的是3.4中提到的基础SLOPE ONE方案的准确性比BIAS FROM MEAN还要高。
在3.5和3.6部分提到的对基础SLOPE ONE进行扩充的算法确实改进了在EachMovie数据集上的准确性。SLOPE ONE算法和WEIGHTED SLOPE ONE之间只存在一点点差距(大概1%)。将不喜欢和喜欢的评论分开的处理能够将结果提高1.5%-2%。
最后,我们一方面对比了基于记忆的PEARSON方案,另一方面也对比了slope one方案。slope one算法取得了一个相对于PEARSON更具准确性的的结果。这个结果足够支持我们声称的slopeone算法是更合理准确的,尽管他们很简单以及其他理想的特点。
5 结论
本文展示了一个易于实现的基于平均评分误差的CF模型,它可以与更多昂贵的基于记忆的方案进行竞争。与目前使用的方案相反,使用我们的方法能够满足5个对抗目标。slope one方案易于实施,动态可更新,在查询时有效,并且对于第一次访问的用户不期望有太多的信息,但相对于其他经常报道的模型依然具有相当的准确性(例如,对于MovieLens,1.90对1.88 MAE)。相比之下,给定一个相对复杂的基于记忆的模型来说slope one算法更为卓越。我们方法的进一步创新是将评论分成不喜欢和喜欢子集,这是一种能够提高准确性的有效技术。希望这里提出的通用型的slope one算法能够给CF算法舍去提供一个有用的参考方案。
。
请注意,截至2004年11月,WEIGHTED SLOPE ONE是Bell / MSN网站在Disverver.net中使用的协同过滤算法。