
14.【模型融合】经典模型融合办法:线性模型和树模型的组合拳
推荐系统在技术实现上一般划分为三个阶段:挖掘、召回、排序。
- 挖掘就是对用户和物品做非常深入的结构化分析,各个角度各个层面的特征都被呈现出来,并且建好索引,供召回阶段使用,大部分挖掘工作都是离线进行的。
- 召回,因为物品太多了,每次给一个用户计算推荐结果时,如果对全部物品挨个计算,那将是一场灾难,取而代之的是用一些手段从全量的物品中筛选出一部分比较靠谱的。
- 排序,针对筛选出的一部分靠谱的做一个统一的论资排辈,最后这个统一的排序就是下面的主题:融合。
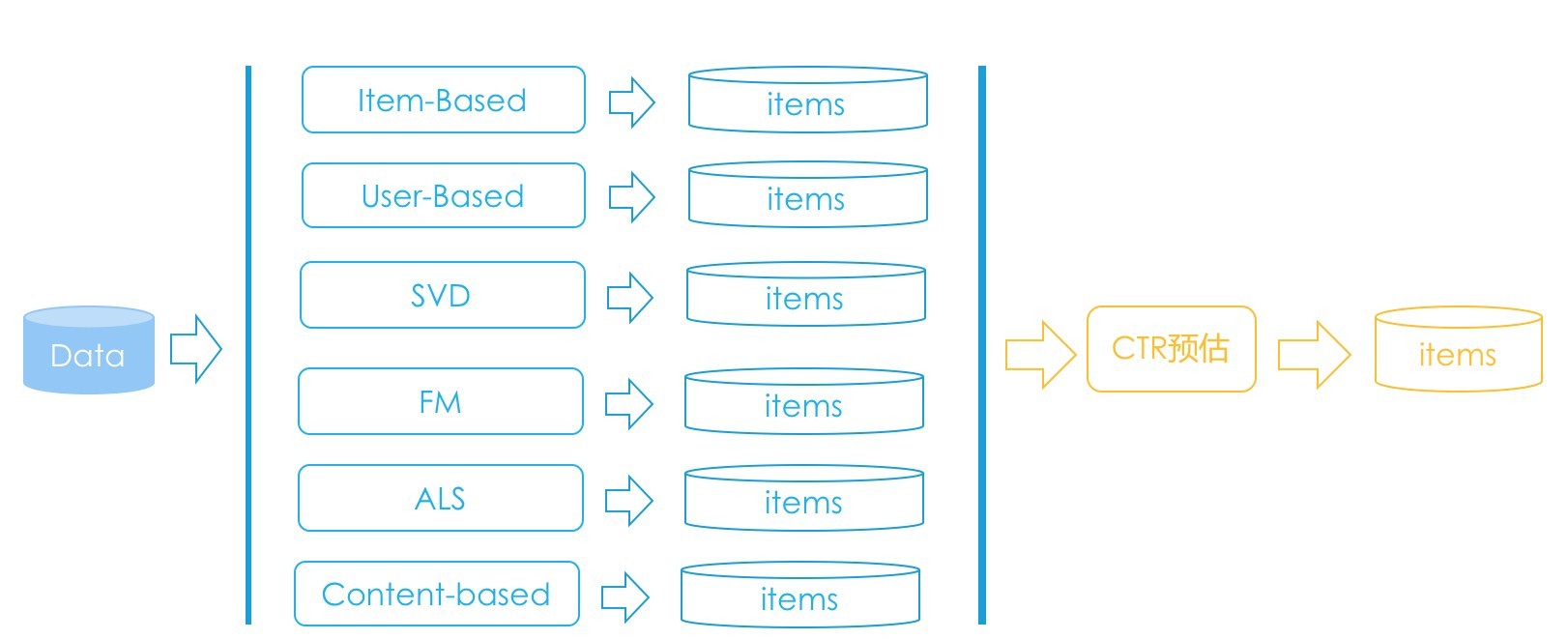
可以注重学习一下图中的SVD,FM以及ALS算法。
多种算法推出推荐结果后,需要模型融合的原因:
- 有的算法可能只给出结果,不给分数,比如用决策树产生一些推荐结果;
- 每种算法给出结果时如果有分数,分数的范围不一定一样,所以不能互相比较,大家各自家庭背景不一样;
- 即使强行把所有分数都归一化,仍然不能互相比较,因为产生的机制不同,有的可能普遍偏高,有的可能普遍偏低。
融合促使集成学习的诞生,下面的典型的模型融合方案是:逻辑回归和梯度提升决策树组合,又名“辑度组合”。
“辑度组合”原理
在推荐系统的模型融合阶段,就要以产品目标为导向。例如,信息流推荐需要以CTR为导向。
逻辑回归
逻辑回归常常被选来执行这个任务,它的输出值范围就是 0 到 1 之间,刚好满足点击率预估的输出,这是一个基础。因为逻辑回归是广义线性模型,相比于传统线性模型,在线性模型基础上增加了 sigmoid 函数。
在对召回阶段不同算法给出的候选物品计算 CTR 预估时,需要两个东西:
- 特征;
- 权重。
- 第一个是特征,就是用量化、向量的方式把一个用户和一个物品的成对组合表示出来。这里说的量化方式包括两种:实数和布尔。假设为x。
- 第二个是权重,每个特征都有一个权重,权重就是特征的话事权。假设为w。
sigmoid函数为:
函数的图像如下:
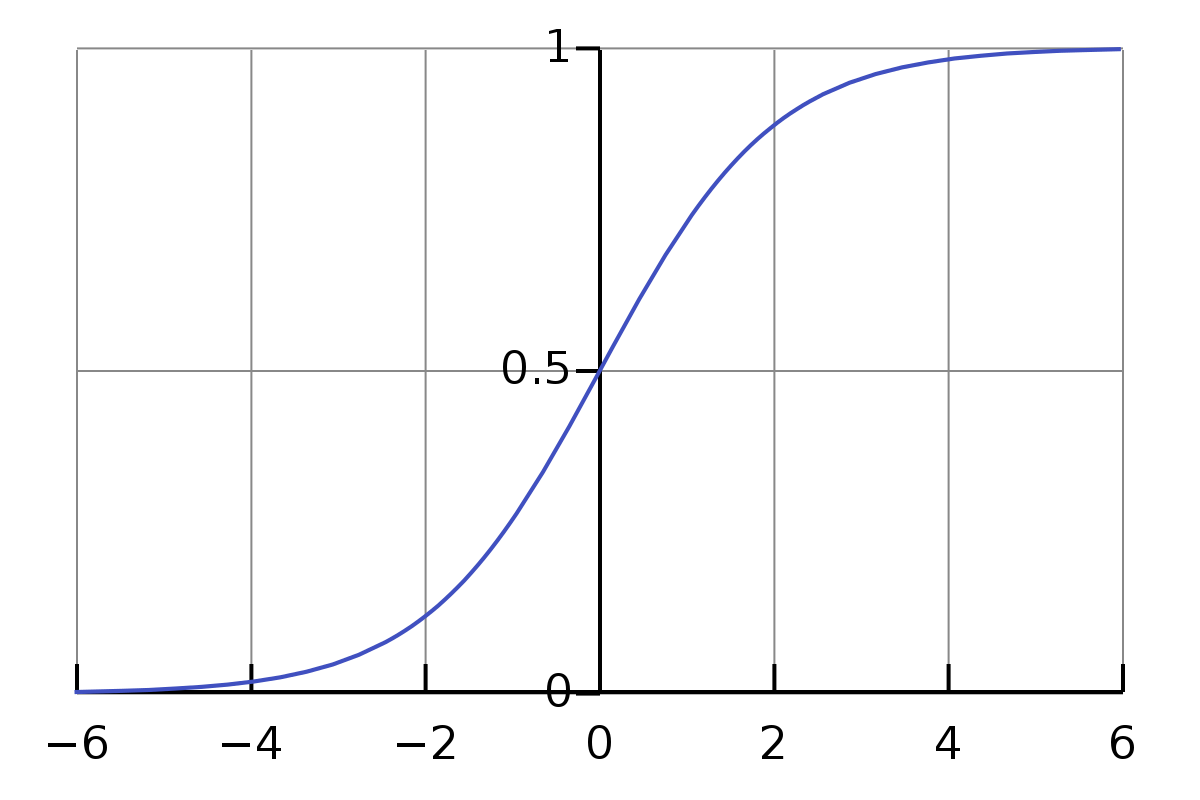
逻辑回归特征的取值都要求要在 0 到 1 之间。
CTR预估,发现CTR预估一般都是用LR,而且特征都是离散的。
0、 离散特征的增加和减少都很容易,易于模型的快速迭代;
1、稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
2、离散化后的特征对异常数据有很强的鲁棒性;
3、逻辑回归属于广义线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于为模型引入了非线性,能够提升模型表达能力,加大拟合;
4、 离散化后可以进行特征交叉,加入特征 A 离散化为M个值,特征B离散为N个值,那么交叉之后会有M*N个变量,进一步引入非线性,提升表达能力;
5、特征离散化后,模型会更稳定,比如如果对用户年龄离散化,20-30作为一个区间,不会因为一个用户年龄长了一岁就变成一个完全不同的人。
6、特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险。
特征组合的难点在于:组合数目非常庞大,而且并不是所有组合都有效,只有少数组合有效。
特征工程 + 线性模型,是模型融合、CTR 预估等居家旅行必备。
- 权重的学习主要看两个方面:损失函数的最小化,就是模型的偏差是否足够小;另一个就是模型的正则化,就是看模型的方差是否足够小;
- 除了要学习出偏差和方差都较小的模型,还需要能够给工程上留出很多余地,具体来说就是两点,一个是希望越多权重为 0 越好,权重为 0 称之为稀疏,可以减小很多计算复杂度,并且模型更简单,方差那部分会可控。
- 另一个是希望能够在线学习这些权重,用户源源不断贡献他们的行为,后台就会源源不断地更新权重,这样才能实现生命的大和谐。
随机梯度下降常被人诟病的是,它什么也表现不好,很难得到稀疏的模型,效果收敛得也很慢。
Google 在 2013 年 KDD 上发表了新的学习算法:FTRL,一种结合了 L1 正则和 L2 正则的在线优化算法,现在各家公司都采用了这个算法。
梯度提升决策树 GBDT
树模型天然就可以肩负起特征组合的任务,从第一个问题开始,也就是树的根节点,到最后得到答案,也就是叶子节点,这一条路径下来就是若干个特征的组合。树模型最原始的是决策树,简称 DT,先驱们常常发现,把“多个表现”略好于“随机乱猜”的模型以某种方式集成在一起往往出奇效,所以就有树模型的集成模型。最常见的就是随机森林,简称 RF,和梯度提升决策树,简称 GBDT。把它分成两部分:一个是 GB,一个是 DT。GB 是得到集成模型的方案,沿着残差梯度下降的方向构建新的子模型,而 DT 就是指构建的子模型要用的决策树。
GBDT 和其他提升算法的不同之处,比如和 Ada boost 算法不同之处,GBDT 用上一棵树去预测所有样本,得到每一个样本的残差,下一棵树不是去拟合样本的目标值,而是去拟合上一棵树的残差。在得到所有这些树后,真正使用时,是将它们的预测结果相加作为最终输出结果。
此处有几个问题:
- 既然是用来做回归的,如何把它用来做分类呢?可以把损失函数从上面的误差平方和换成适合分类的损失函数,例如对数损失函数。CTR预估的损失函数可以定义为:
- 通常还需要考虑防止过拟合,也就是损失函数汇总需要增加正则项,正则化的方法一般是:限定总的树个数、树的深度、以及叶子节点的权重大小。
- 构建每一棵树时如果遇到实数值的特征,还需要将其分裂成若干区间,分裂指标有很多,可以参考 xgboost 中的计算分裂点收益,也可以参考决策树所用的信息增益。
二者结合
将两者(LR+GBDT)结合在一起,用于做模型融合阶段的 CTR 预估。这是 Facebook 在其广告系统中使用的方法,其中 GBDT 的任务就是产生高阶特征组合。
具体的做法是:GBDT 产生了 N 棵树,一条样本来了后,在每一棵树上都会从根节点走到叶子节点,到了叶子节点后,就是 1 或者 0,或者不变。把每一棵树的输出看成是一个组合特征,取值为 0 或者 1,一共 N 棵树就会产生 N 个新的特征,这 N 个新的特征作为输入进入 LR 模型,输出最终的结果。如下图所示:
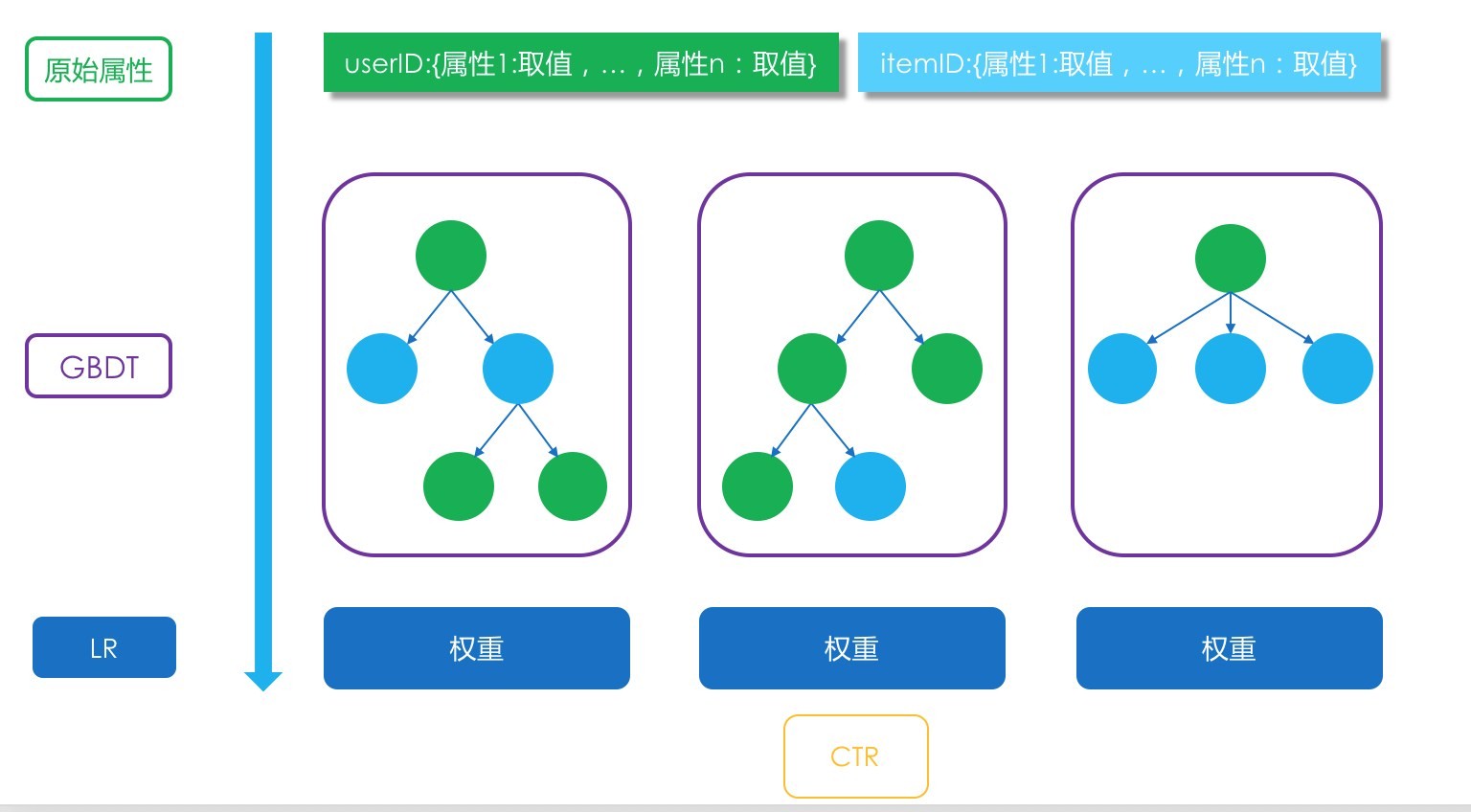
虽然简单,但在实际应用中非常的有效。
15.【模型融合】一网打尽协同过滤、矩阵分解和线性模型
从特征组合说起
对逻辑回归 朴素的特征组合就是二阶笛卡尔乘积,但是你有没有想过这样暴力组合的问题所在。
- 两两组合导致特征维度灾难;
- 组合后的特征不见得都有效,事实上大部分可能无效;
- 组合后的特征样本非常稀疏,意思就是组合容易,但是并不能在样本中找到对应的组合出现,也就没办法在训练时更新参数。
如果把包含了特征两两组合的逻辑回归线性部分写出来,就是:
问题就是两两组合后非常有可能没有样本能够学习到 $w_{ij}$,不但没有样本可以用来学习到参数,而且在应用时,如果遇到了这样的组合,也就只能放弃,因为没有学到权重。针对这个问题,就有了一个新的算法模型:因子分解机模型,也叫做 FM,即 Factorization Machine。因子分解机也常常用来做模型融合
FM模型
1 原理
作者在2010提出此模型,思想是对上面那个公式中的 $w_{ij}$ 做解耦,让每一个特征学习一个隐因子向量出来。任何两个特征不小心在实际使用时相遇了,需要组合,那么各自掏出自己随身携带的隐因子变量做一个向量点积,就是两者组合特征的权重了。
针对logistic回归的线性部分:
不同之处就是原来有个$w_{ij}$,变成了这里的两个隐因子向量的点积。它其实认为两个特征之间,即使没有共同出现在一条样本中,也是有间接联系的。例如A和B有关系,B和C有关系,通过点积可以体现出A和C有关系。
2 模型训练
因子分解机的参数学习并无特别之处,看目标函数,在这里是把它当作融合模型来看的,用来做 CTR 预估,因此预测目标是一个二分类,因子分解机的输出还需要经过 sigmoid 函数变换:
因此,损失目标函数也就是常用的 logistic loss:
公式中 $\sigma(\hat y)$ 是因子分解机的预测输出后,经过 sigmoid 函数变换得到的预估 CTR,$y_(i)$ 是真实样本的类别标记,正样本是 1,负样本是 0,m 是样本总数。
注意损失函数实际上还需要加上正则项。
3 预测阶段
因子分解机中二阶特征组合那一坨,在实际计算时,复杂度有点高,如果隐因子向量的维度是 k,特征维度是 n,那这个复杂度就是 $O(kn^2)$。
其中 n 方是特征要两两组合,k 是每次组合都要对 k 维向量计算点积。可以如下改造:
伪代码:
loop1 begin:循环k次,k就是隐因子向量的维度,其中,循环到第f次时做一下事情;
loop2 begin:循环n个特征,第i次循环时做这样的事情:
1. 从第i个特征的隐因子向量中拿出第f维的值;
2. 计算两个值:A是特征值和f维的值相乘,B是A的平方;
loop2 end
把n个A累加起来,并平方得到C,把n个B也累加起来,得到D,用C减D得到E;
loop1 end
把k次循环得到的k个E累加起来,除以2。
二阶组合部分的实际计算方法,现在这样做的复杂度只是 O(kn)
4. 一网打尽其他模型
如下图示例的样本:
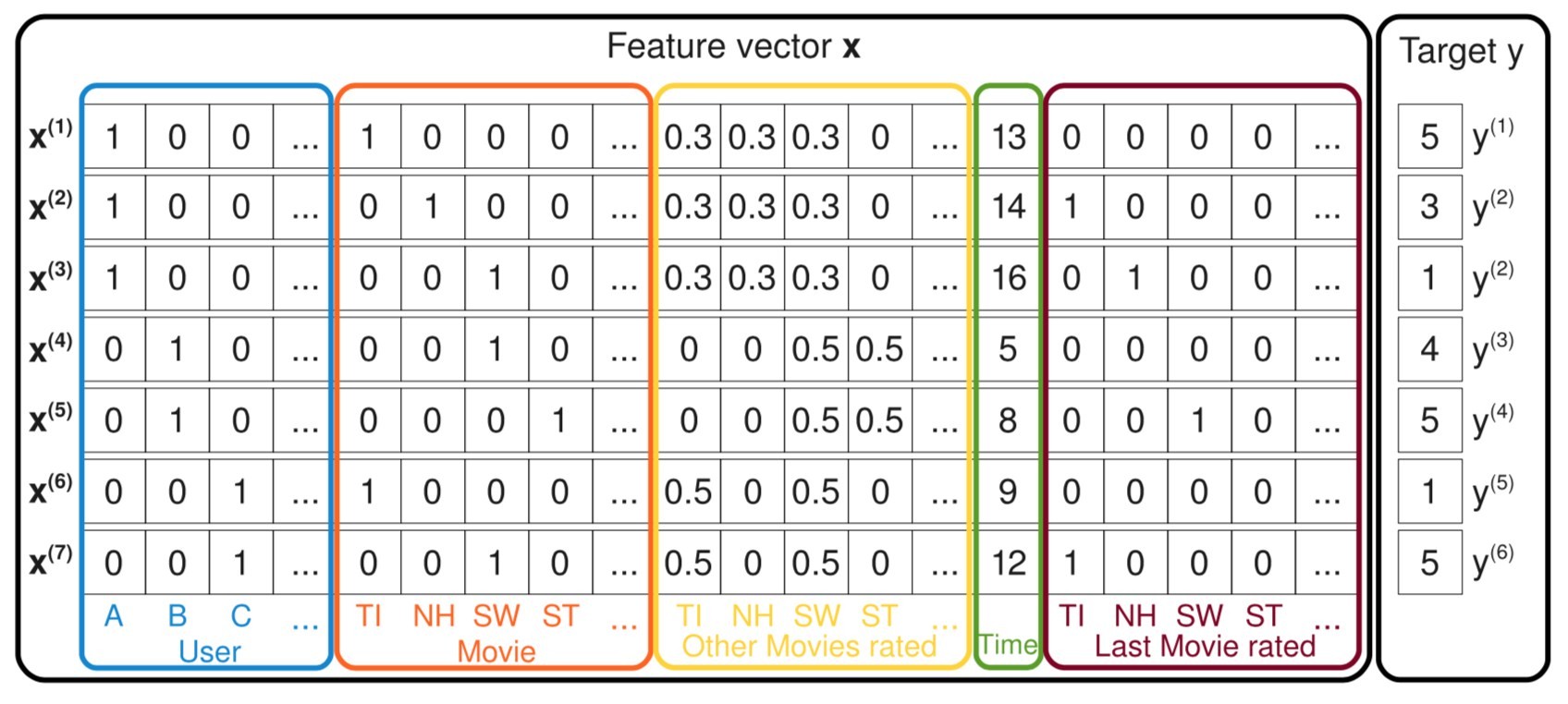
这张图中每一条样本都记录了用户对电影的评分,最右边的 y 是评分,也就是预测目标;左边的特征有五种,用户 ID、当前评分的电影 ID、曾经评过的其他分、评分时间、上一次评分的电影。
因子分解机可以实现带有特征组合的逻辑回归。假设图中的样本特征只留下用户 ID 和电影 ID,因子分解机模型就变成:
因为用户 ID 和电影 ID,在一条样本中,各自都只有一个维度是 1,其他都是 0,所以在一阶部分就没有了求和符合,直接是 wu 和 wi,二阶部分特征乘积也只剩下了一个 1,其他都为 0 了。这不就是带有偏置信息的 SVD 吗?在 SVD 基础上把样本中的特征加上用户历史评过分的电影 ID,再求隐因子向量,就是 SVD++!再加上时间信息,就变成了 time-SVD。
5.FFM
改进的思路是:不但认为特征和特征之间潜藏着一些不可告人的关系,还认为特征和特征类型有着千丝万缕的关系。这个特征类型,就是某些特征实际上是来自数据的同一个字段,比如用户 ID,占据了很多维度,变成了很多特征,但他们都属于同一个类型,都叫“用户 ID”。这个特征类型就是字段,即 Field。这种改进叫做 Field-aware Factorization Machines,简称 FFM。
因子分解机是:
FFM 改进的是二阶组合那部分,改进的模型认为每个特征有 f 个隐因子向量,这里的 f 就是特征一共来自多少个字段(Field),二阶组合部分改进后如下:
FFM 模型也常用来做 CTR 预估。在 FM 和 FFM 事件过程中,记得要对样本和特征都做归一化。
16.【模型融合】深度和宽度兼具的融合模型 Wide and Deep
要深还是要宽
融合排序,最常见的就是 CTR 预估。这里的C可以是点击,收藏,分享以及购买等等。CTR 预估的常见做法就是广义线性模型,如 Logistic Regression,然后再采用特征海洋战术,就是把几乎所有的精力都放在搞特征上:挖掘新特征、挖掘特征组合、寻找新的特征离散方法等等。
这种简单模型加特征工程的做法好处多多:
- 线性模型简单,其训练和预测计算复杂度都相对低;
- 工程师的精力可以集中在发掘新的有效特征上,俗称特征工程;
- 工程师们可以并行化工作,各自挖掘特征;
- 线性模型的可解释性相对非线性模型要好。
深度学习在推荐领域的应用,其最大好处就是“洞悉本质般的精深”,优秀的泛化性能,可以给推荐很多惊喜。Google 在 2016 年就发表了他们在 Google Play 应用商店上实践检验过的 CTR 预估方法:Wide & Deep 模型,让两者一起为用户们服务,这样就取得了良好效果。具体的可以参考这篇论文:Cheng H T, Koc L, Harmsen J, et al. Wide & Deep Learning for Recommender Systems[J]. 2016:7-10.
Wide & Deep 模型
推荐系统有召回和排序两部构成,不过,推荐系统的检索过程并不一定有显式的检索语句,通常是拿着用户特征和场景特征去检索召回,其中用户特征也就是在前面的专栏中提到的用户画像。
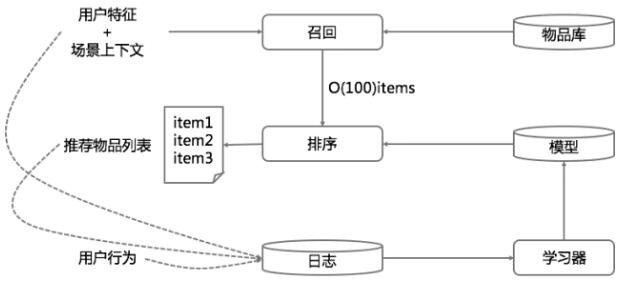
深宽模型就是专门用于融合排序的,分成两部分来看。一部分是线性模型,一部分是深度非线性模型。整个示意图如下:
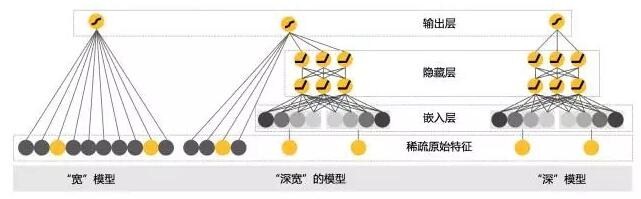
首先,线性模型部分,也就是“宽模型”,形式如下:
这是线性模型的标准形式,逻辑回归只是在这基础上用 sigmoid 函数变换了一下。深度模型其实就是一个前馈神经网络。深度模型对原始的高维稀疏类别型特征,先进行嵌入学习,转换为稠密、低维的实值型向量,转换后的向量维度通常在 10-100 这个范围。这里的嵌入学习,就是先随机初始化嵌入向量,再直接扔到整个前馈网络中,用目标函数来优化学习。
深度模型中增加隐藏层的含义就是提供了非线性转换。所谓深度学习,就是深度神经网络,就是有不止一层的隐藏层存在。层数越多,非线性越强,模型越复杂。还有两点需要说明:
- 隐藏层的激活函数不一定是 sigmoid 函数,甚至往往不用 sigmoid 函数;
- 输出层的函数也不一定是 sigmoid 函数,这个根据预测目标而定,回归任务就是 i 直接输出求和部分,二分类是 sigmoid 函数,多分类则是 softmax。
深模型中,每一个隐藏层激活方式表示如下:
其中 l 表示第 l 个隐藏层,f 是激活函数,通常选用 ReLU,也叫整流线性单元,为什么选用ReLU 而不是 sigmoid 函数,原因主要是 sigmoid 函数在误差反向传播时梯度容易饱和。
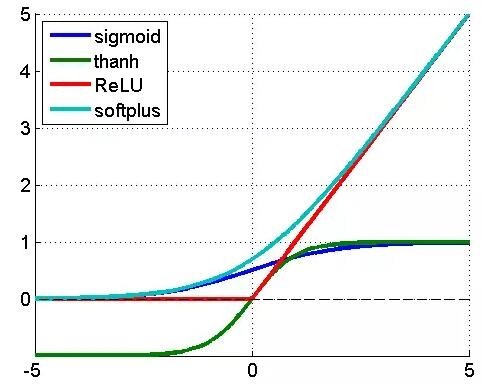
- 紫色是 sigmoid 函数,就是逻辑回归用的那个,输入值是任意范围,输出是 0 到 1 之间;
- 草绿色是反正切函数,和 sigmoid 函数样子很像,输入值是任意范围,输出是 -1 到 1 之间;
- 红色就是 ReLU 函数,当输入小于 0 时,输出为 0,当输入大于 0 时,输出等于输入;
- 蓝色是 softplus 函数,是一条渐近线,输入趋向于负无穷时,输出趋于 0,输入趋于正无穷时,输出趋向于等于输入。
最后,看看两者的融合,即深宽模型。深模型和宽模型,由逻辑回归作为最终输出单元,深模型最后一个隐藏层作为特征接入逻辑回归,宽模型的原始特征与之一起接入逻辑回归,然后训练参数。参数学习就是通常说的端到端,把深模型和宽模型以及最终融合的权重放在一个训练流程中,直接对目标函数负责,不存在分阶段训练。它与机器学习中的集成学习方法有所区别,集成学习的子模型是独立训练的,只在融合阶段才会学习权重,这里是整体。
上述输出公式中,Y 是我们要预估的行为,二值变量,如购买,或点击,Google 的应用场景为“是否安装APP”。$\sigma$是 sigmoid 函数,$W{wide}^T$ 宽模型的权重,$\Phi(X)$ 是宽模型的组合特征,$W{deep}^T$ 应用在深模型输出上的权重,$a^{(lf)}$ 是深模型的最后一层输出,b 是线性模型的偏置。
几点技巧
这个深宽模型已经在 TensorFlow 中有开源实现,具体落地时整个数据流如下图所示:
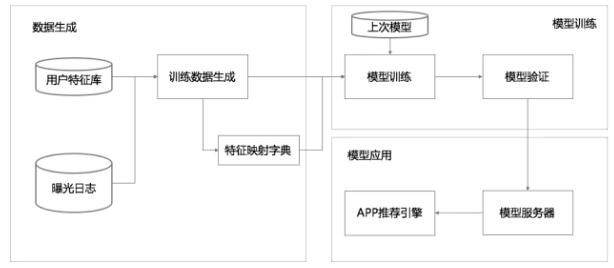
整个流程分为三大块:数据生成,模型训练,模型应用。
1 数据生成
几个要点:
- 每一条曝光日志就生成一条样本,标签就是 1/0,安装了 App 就是 1,否则就是 0。
- 将字符串形式的特征映射为 ID,需要用一个阈值过滤掉那些出现样本较少的特征。
- 对连续值做归一化,归一化的方法是:对累积分布函数 P(X<=x) 划分 nq 个分位,落入第 i 个分位的特征都归一化为下列所示:$\frac {i-1}{n_q-1}$
2 模型训练
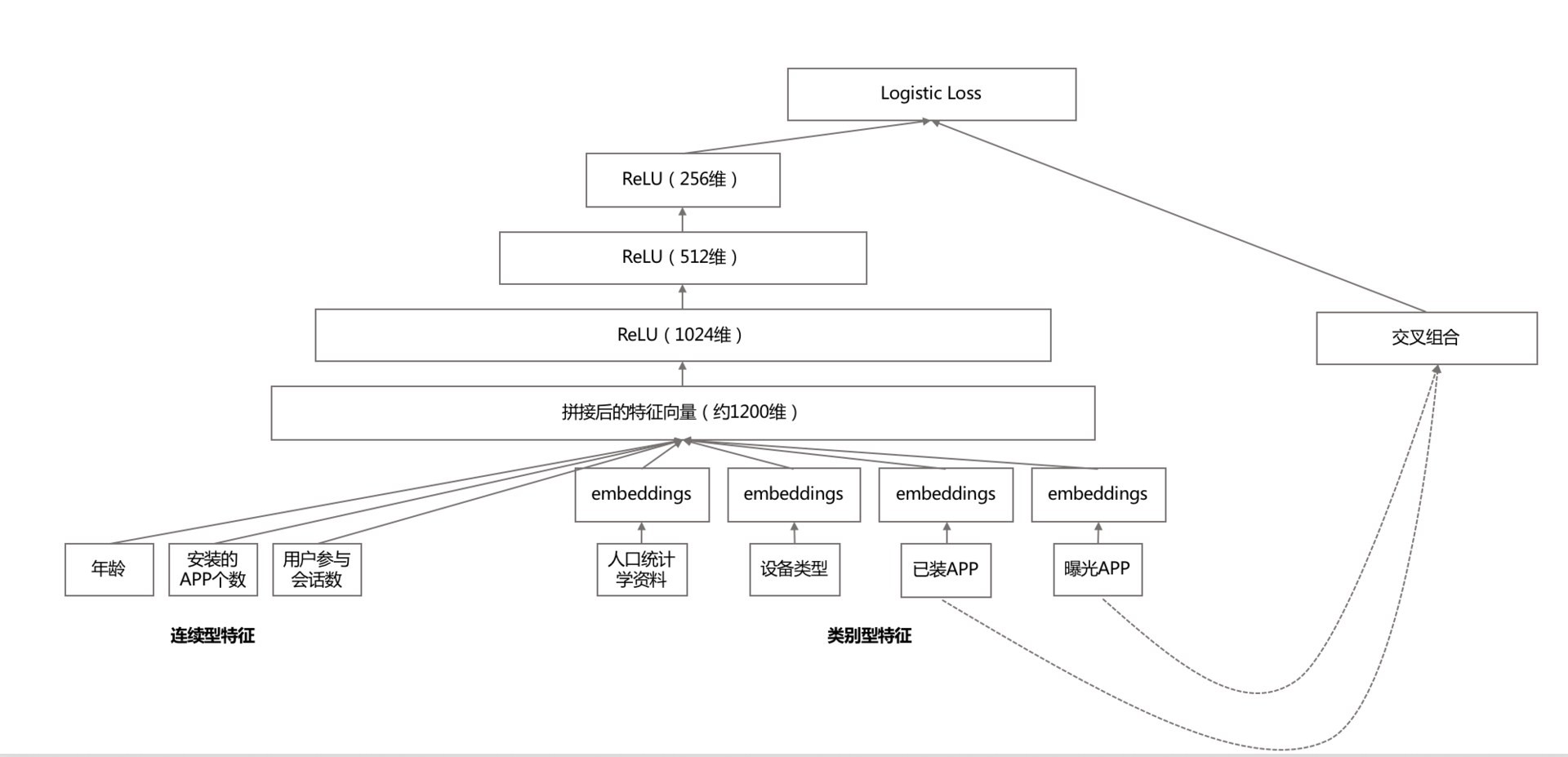
其要点,在深度模型侧:
- 每个类别特征 embedding 成一个 32 维向量;
- 将所有类别特征的 embedding 变量连成一个 1200 维度左右的大向量;
- 1200 维度向量就送进三层以 ReLU 作为激活函数的隐藏层;
- 最终从 Logistic Regreesion 输出。
宽模型侧就是传统的做法:特征交叉组合。
3 模型应用
模型验证后,就发布到模型服务器。模型服务,每次网络请求输入的是来自召回模块的 App 候选列表以及用户特征,再对输入的每个 App 进行评分。评分就是用我们的“深宽模型”计算,再按照计算的 CTR 从高到低排序。为了让每次请求响应时间在 10ms 量级,每次并不是串行地对每个候选 App 计算,而是多线程并行,将候选 App 分成若干并行批量计算。