
因式分解机
摘要:在本文中,我们介绍了一种因式分解机,这是一种新的模型,结合了SVM的优点,利用了因式分解模型。类似SVM,因式分解机是一种通用的预测器,可以适用于任意的实值特征向量。对比SVM,FMs利用因式分解对变量之间的关系进行建模。因此,FMs可以在大量稀疏特征中进行相互关系的估计。我们展示了,模型的表达式可以在线性时间内求解,FMs可以进行直接的优化。所以,不像非线性的SVM,不需要进行对偶变换,模型的参数可以直接的进行估计,不需要用到支持向量。我们展示了和SVM的关系,以及在稀疏的设置下的参数估计的优势。
另外,有许多因式分解模型如矩阵分解,并行因子分析如SVD++,PITF,FPMC。这些方法的缺点是通用性不好,只对特殊的输入数据有用。优化方法对于不同的任务也各不相同。我们展示了,FMs通过制定不同的输入就可以模拟这些模型。这就使得FMs非常的易用,甚至可以不需要分解模型的专业知识都可以。
1、介绍
SVM是机器学习和数据挖掘中最流行的算法之一。然而在协同过滤的场景中,SVM并不重要,最好的模型要么直接使用矩阵的因式分解或者使用因式分解参数。本文中,我们会展示,SVM之所以在这些任务中表现不好,是因为SVM在复杂的非线性的稀疏的核空间中很难找到一个好的分割超平面。而张量分解模型的缺点在于(1)不用应用于标准的预测数据(2)不同的任务需要特殊的模型设计和学习算法。
在本文中,我们介绍了一个新的预测器,Factorization Machine(FM),是一个像SVM一样的通用的预测模型,但是可以在非常稀疏的数据中估计出可靠的参数。FM对所有变量的相互关系的进行建模(对比SVM的多项式核),但是利用了可因式分解的参数,而不是像SVM一样使用了稠密的参数。我们展示了,模型的表达式可以在线性时间内求解,而且只依赖与线性数量大小的参数。这就允许了直接进行优化和存储模型的参数,而不需要存储任何的训练数据。(SVM是需要存储支持向量的)。非线性的SVM通常使用对偶形式进行求解,而且会使用到支持向量。我们也显示了在协同过滤的业务上FMs比许多很成功的模型如带偏置的MF,SVD++,PITF,FPMC等都好。
总的来说,我们提出的FM的优点有:
1)FMs可以在非常稀疏的数据上进行参数估计。
2)FMs的复杂度是线性的,方便优化,不像SVM需要依赖支持向量。我们证明FM可以扩展应用在大数据集上,例如有1亿训练样例的Netflix数据集。
3)FMs是通用的预测模型,可以适用于任意的实值的特征向量。与此相反,其他先进的分解模型只在特定输入数据的情况下起作用。我们将通过定义输入数据的特征向量来证明这一点,FM可以模仿其他最先进的模型例如带偏置项的MF,SVD++,PITF以及FPMC模型。
2、在稀疏数据下进行预测
大部分的常用的预测任务是估计一个预测的函数$y:\mathbb{R}^n \rightarrow T$,从一个实数向量$x \in \mathbb{R}^n$到目标$T$(如果是回归任务$T=R$,如果是分类任务$T={+,-}$)。在监督学习中,假设有个给定y值的样本训练数据集$D = \{(x^{(1)},y^{(1)}),(x^{(2)},y^{(2)}),…\}$。我们也研究了排序的任务,拥有目标值$T=\mathbb{R}$的函数y可以适用于对x向量的评分和排序。评分函数可以通过成对的数据进行训练,当一个样本组合$(x_{(A)},x_{(B)})\in D$表示$x_{(A)}$应该排在$x_{(B)}$的前面。由于成对数据是反对称的,可以直接使用正的实例。
在本文中,我们要解决的问题是数据的稀疏问题,也就是说在x向量中,大部分的值都是0,只有少部分不是0。让$m(x)$表示特征向量x中非0元素的个数,$\bar m_D$表示所有特征向量$x \in D$的非零元素个数$m(x)$的平均值。高稀疏性的特征在现实世界中是非常常见的,如文本分析和推荐系统中。高稀疏性的一个原因是在处理超多类别变量域的潜在问题。
例1 假设我们有个电影评分系统的交互数据。系统记录了用户$u\in U$在特定的时间$t \in R$对电影$i \in I$的评分$r \in {1,2,3,4,5}$.用户U和电影I为:
$U = \{Alice (A), Bob (B), Charlie (C), . . .\}$
$I = \{Titanic (TI),Notting Hill (NH), Star Wars (SW),Star Trek (ST), . . .\}$
用观察到的数据S表示:
$S = \{(A, TI, 2010-1, 5), (A,NH, 2010-2, 3), (A, SW, 2010-4, 1),$
$(B, SW, 2009-5, 4), (B, ST, 2009-8, 5),$
$(C, TI, 2009-9, 1), (C, SW, 2009-12, 5)\}$
任务是使用这些数据,估计一个函数$\hat y$,这个函数能够预测一个用户在某个时间对某个电影的评分。

图1展示了一个示例,在这个任务中如何从观测数据S中构建特征向量。在这里,首先$|U|$是一个二值示性变量(蓝色的),它表示一个交互中活跃的用户,总是可以确定的是在一次交互$(u,i,t,r) \in S$中有一个确定的活跃用户。例如,第一行中的Alice($x_A^{(1)} = 1$)。下一个二值示性变量$|I|$(红色的)表示活跃的物品,同样的总是有一个活跃的物品,例如$x_{TI}^{(1)}=1$。图1中的特征向量也包含了用来表示用户曾经评价过的其他物品的表示向量(黄色的)。对于每个用户来说,变量均是被归一化之后的。例如Alice评价过Notting Hill 和 Star Wars。此外,样本还包含一个从2019年一月开始的月份向量(绿色的)来表示时间。最后几列表示用户评价过的最后一个电影,最右边的是当前电影的评分y。在第五部分,我们将展示因式分解机是如何利用输入数据中的特征向量来做到最特殊的顶级的因式分解模型的。
我们将通过这篇论文用这个示例数据集来证明。然而,请注意FMs是一个像SVMs一样的通用模型,可以应用在任何一个现实中的特征向量,并且对推荐系统没有什么限制。
3.因式分解机(FM)
在这一部分,我们将来介绍因式分解机。我们会详细地讨论模型中的公式推导,并且会展示怎么使用FMs进行多预测任务。
A. 因式分解模型
1)模型方程:2维的因式分解机模型方程:
公式中的模型参数必须在下面的值域中进行估计:
其中,$ \langle ·,· \rangle $表示长度为k的点乘,k是一个超参数:
V中的行向量$v_i$表示第k个因子的第i个变量。$k \in \mathbb{N}_0^+$是一个产参数定义了因式分解的维度。
一个2阶的FM能过获取所有的单个特征和配对特征的相互关系:
- $w_0$是全局偏置项。
- $w_i$是模型中的第i个变量的权重。
- $ \hat w_{i,j}:= \langle v_i,v_j \rangle $表示模型中第i个变量和第j个变量之间的交互项。如此就不是用唯一的模型参数$w_{i,j} \in \mathbb{R}$来作为FM模型中因式分解交互项的权重了。在后面我们将看到,当遇到高维且稀疏的数据的时候,这是进行高质量参数估计的关键点。
2)表达能力:我们知道对于正定矩阵W,存在矩阵V,使得$W=V\cdot V^t$,k足够大。这表明了当k足够大的时候FM能够表示矩阵W中的任何交互项。然而对于稀疏的情况,应该选择一个比较小的k,因为没有足够的数据去预测一个复杂的W。限制k,也就是FM的表达能力,能够提高稀疏情况下的相互关系矩阵的泛化性能。
3)稀疏情况下的参数估计:在稀疏情况下,通常没有足够的数据进行直接的参数估计。因式分解机可以进行稀疏的估计,甚至在稀疏的情况下可以估计的很好,这是因为它打破了交互项参数和因式分解之间的独立性。总的来说是因为进行了因式分解之后,用来估计一个参数的数据也可以用来估计相关的另一个参数。我们将利用图1中的数据举个例子来更清晰地描述我们的想法。假设我们想估计Alice(A)和Star Trek(ST)交互项的参数来预测目标值y(这里是评分)。很显然,在一个样本中,两个用户$x_A,x_{ST}$的参数不会都是非0数,如果直接进行估计的话,那么A和ST的相互关系参数会估计成0。但是如果使用因式分解将参数分解长$ \langle v_A,v_{ST} \rangle $的话,在这个案例中我们就可以直接进行估计了。
4)计算量:接下来,我们展示如何让FMs变得实际可用。前面提到的方程(1)的计算复杂度是O(kn2),因为所有的称为交互项必须倍计算。但是改变一下之后将会使其复杂度降低到线性的。
引理3.1:因式分解机的计算复杂度可以变成线性的时间复杂度O(kn)。
证明:由于所有的成对交互项都会做因式分解,于是模型中就没有需要直接利用两个变量进行直接估计的参数。所有成对的交互项可以进行如下的变化:
以上的公式的结果仅仅有线性的计算复杂度,当k和n固定的时候,计算复杂度就为O(kn)。
进一步,在稀疏性的条件下,x中的大部分元素值都是0,因此求和就可以只在非0的元素中进行。因此在稀疏数据中因式分解机的计算复杂度就在$O(k\bar m_D)$,例如当$\bar m_D=2$时就是一个经典的推荐系统例如MF算法。
B. 使用因式分解机进行预测
因式分解机可以用在各种预测任务中:
- 回归:直接进行预测,使用最小均方误差进行优化。
- 二分类:使用合页损失或者对数几率损失进行优化。
- 排序:对预测的分数进行排序,可以通过成对实例的分类损失进行优化。
在上面所有的情况下,都可以使用L2的正则化来防止过拟合。
C. 因式分解机的学习
我们已经证明,FMs有一个确定的模型公式使其计算复杂度达到线性的。因此,FMs的参数$(w_0,w , V)$可以通过梯度下降的方式来求解,例如随机梯度下降法(SGD).FM模型的梯度是:
其中,求和项$\sum_{j=1}^n v_{j,f}x_j$是和i无关的,可以事先求出来。总的来说,每个梯度都可以在O(1)时间内求得。对于给个案例(x,y)整体的参数更新的时间为O(kn),稀疏数据的时候则为O(km(x))。
我们提供了一个通用的实现,LIBFM,使用SGD,支持元素和配对的loss。
D. d阶的因式分解机
2阶的因式分解机可以很容易的推广到d阶:
其中,第l个相互关系参数可以通过PARAFAC模型进行因式分解:
通过变换,同样可以在线性的时间复杂度上求解,复杂度降为$O(k_d n^d)$。
E. 总结
FMs的优点:
1)可以在稀疏的情况下进行很好的参数估计,特别是可以估计没有观测到的相互关系。
2)参数的大小和运算时间都是线性的,可以通过SGD进行参数的更新,可以使用多种loss。
4、FMs vs. SVMs
A. SVM模型
我们知道SVM可以表示成变换后的特征向量x和参数w的内积的形式:$\hat y(x) = \langle \phi (x),w \rangle $,其中$\phi$是一个映射将特征空间$\mathbb{R}^n$映射到一个更复杂的空间$\mathcal{F}$。这个映射通常使用核函数来进行:
下面我们通过分析SVMs主要形式来讨论FM和SVM之间的关系。
1)线性核:最简单的核函数就是线性核:$ K_l(x,z):=1 + \langle x,z \rangle $,这对应的映射就是$\phi (x) := (1,x_1, \cdots , x_n)$。因此线性核的SVM模型等式可以重写为:
很明显可以发现线性的SVM模型和FM为1阶的情况完全等效
2)多项式核:多项式的核函数可以让SVM模型去拟合更高维的变量交互项。可以定义:$K(x,z) := ( \langle x,z \rangle + 1)^d$。例如当多项式为2阶的时候,对应如下的映射:
因此,多项式核函数的SVM模型等式可以重写为:
其中模型的参数是:
对比多项式核函数的SVM模型和FM模型,可以发现的一点是两个模型交互项全部上升到了2维。而这主要的差别是参数:SVMs的所有交互项参数之间是相互独立的。相反,对于FMs模型来说所有的交互项参数都是经过因式分解的,因此$ \langle v_i, v_j \rangle and \langle v_i, v_l \rangle $依赖于各自交叉共享的参数($v_i$)。
B. 稀疏情况下的参数估计
我们下面解释一下为什么线性和多项式的SVM在稀疏的情况下表现不好。我们将使用用户和物品的表征向量的数据来证明这个协同过滤的例子。这里,特征向量是稀疏的,并且仅仅两个参数是非0的。
1)线性SVM:对于这种数据x,线性的SVM模型等价于下面的等式:
因为当且仅当$j = u \ or \ j = i$的时候$x_j = 1$。这个模型对应于一个最基础的协同过滤模型,即只有用户和巫婆的偏置项存在。由于这个模型很简单,因为只有少数的几个参数,所以模型的参数的预测在这种稀疏情况下也会不错。但是预测的质量却不好,见图2。
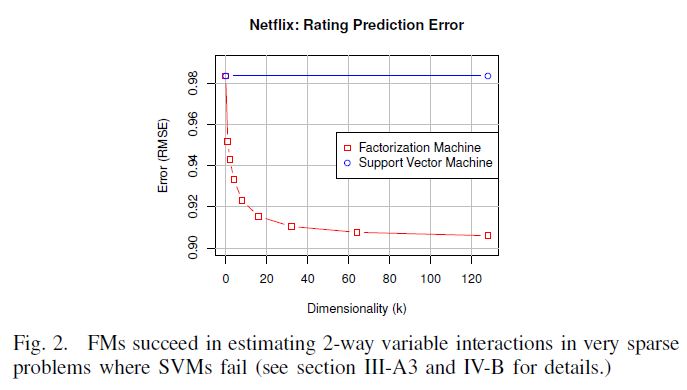
2)多项式SVM:这种情况下,SVM可以获取高阶的相互关系。在我们的系数数据案例中,$m(x)=2$,这时候SVMs模型的等式等价于:
首先,$w_u \ and \ w_{u,u}^{(2)}$代表的是同样的,可以期初其中一个例如后者。现在模型的等式就变成了线性的除了有一个额外的用户交叉项$w_{u,i}^{(2)}$。在经典的协同过滤(FM)问题中,对于每个交叉项参数$w_{u,i}^{(2)}$,训练数据中至少有一个观测样本(u,i),而在测试数据中的案例$(u’,i’)$就一般不会在训练数据及中再次出现了。这意味着对于所有的测试案例(u,i)的交叉项参数来说,最大边际解是0。因此对于预测测试集的时候,多项式SVM对于二阶的交叉项来说没有任何作用;所以多项式核的SVM模型仅仅依赖于用户和物品偏置项,在效果上并没有比线性的SVM好多少。
对于SVM模型,估计一个高级的交叉项并不是CF模型中的问题,但是当数据是高稀疏性的时候这个问题就存在了。因为对于一个成对的交叉项$(i,j)$想要得到一个可靠的参数估计$w_{i,j}^{(2)}$的话,必须提供足够多的样例$x \in D,where \ x_i \neq 0 \wedge x_i \neq 0$。只要不同时出现$x_i=0,x_j=0$,这个样例就可以用来进行参数估计。
总结一下,只要数据比较稀疏的时候,即没有足够的(i,j)的样例的时候,SVMs模型基本上失效的。
C. 总结
1)SVM的稠密的参数需要相互关系的直接的观测值,而在稀疏的输入的情况下,这种直接的观测值很少。但是FMs模型就可以在稀疏的情况将进行很好的参数估计。
2)FMs可以直接进行学习,非线性的SVM通常在对偶形式进行求解。
3)FMs的函数不依赖与训练数据SVM的预测依赖部分训练数据(支持向量)。
5、FMs vs. 其他的因式分解模型
有各种各样的分解模型,从m-ary类别变量关系的标准模型(例如MF,PARAFAC)到用于特定数据和任务的专用模型(例如SVD ++,PITF,FPMC)。接下来,我们展示一下FM可以仅仅通过使用正确的输入数据就可以模仿很多其他的因式分解模型(例如特征向量x)。
A.矩阵和张量分解
矩阵分解(MF)是研究最多的因子分解模型之一。它是分解了在两个分类变量之间的关系(例如U和I)。标准处理分类变量的方法是为每个U和I级别定义二值的指标变量(例如见图1,
第一个(蓝色)和第二个(红色)组):
使用这个特征向量x的FM模型与矩阵分解模型相同,因为$x_j$仅仅在当前u和i是非0的,所以其他的偏置项和交互项都可以舍去:
同样的考虑,当有两个以上的分类变量的时候可以发现存在一样的问题,FM包括了一个嵌套并行因子分析模型(PARAFAC)。
B.SVD++
对于评分预测任务(即回归)来说,Koren将矩阵分解模型改进成了SVD++模型。FM模型就可以使用下列的输入数据来模拟这个模型(就像图一中的前三组):
其中$N_u$是当前用户曾经评论过的所有电影的集合。一个二维的FM模型将以如下方式处理这个数据集:
其中第一部分(即第一行)就等价于一个SVD++模型。但FM还包含一些额外的用户和电影$N_u$之间的交互项,以及$N_u$中电影对之间的电影$N_u$本身和交互项的基础效应。
C.PITF的标签推荐
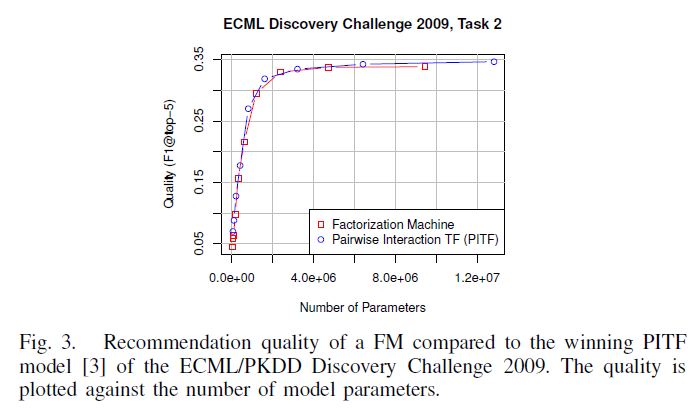
标签预测的问题被定义为对于给定的用户和项目组合来排名标签。这意味着有涉及三个分类域:用户U,项目I和标签T.在关于标签推荐的ECML / PKDD发现挑战中,基于分解成对的交互项的模型(PITF)取得了最好成绩[3]。我们将展示FM如何
可以模仿这个模型。一个对于活动用户u,项目i和标签t有二值表示变量的分解机的可以写成以下模型:
由于该模型用于在相同的用户/项目组合(u,i)内的两个标签$t_A,t_B$之间进行排序的,两者都是始终致力于优化和预测案例$(u,i,t_A)和(u,i,t_B)之间的得分差异。因此对于成对排序的优化,FM模型等价于:
现在二元指标的原始PITF模型和FM模型几乎是相同的。唯一的区别在于(1)FM模型对t具有偏差项$w_t$,(2)$(u,t)-(i,t)$交叉项的标签之间的分解参数$(v_t)$在FM模型中是共享的,但是又不同于原始PITF模型。除了这个理论分析,图3显示了两种模型实现此任务的可比预测质量的经验分布。
D.分解个性化的马尔科夫链
FPMC模型尝试基于用户u的最后一次购买(时间t-1)在线上商店进行商品排序。
再一次仅仅用特征生成,一个二维的因式分解机可以来近似:
其中$B_{t}^u \subseteq L$是一个用户u在时间t可购买的所有物品的集合,然后:
就像标签推荐一样,这个模型被用来优化排名(这里是排序物品i),因此只有$(u,i_A,t)$和$(u,i_B,t)$之间的评分存在差异的时候会被用于预测和优化的评断标准中。因此,所有额外的不依赖于i都可以消失,FM模型的等式就相当于:
现在人们可以看到原始的FPMC模型和FM模型几乎是相同的,仅在附加的偏置项$w_i$中有所不同,以及FM模型中的(u,i)和(i,l)交互项物品的分解参数的共享。
E.总结
1)标准分解模型,如PARAFAC或MF不是像因式分解机这样的一般预测模型。相反,他们需要特征向量被分成m个部分,每个部分都是精确的一个元素是1,其余元素是0。
2)有许多关于专业化因子分解的建议为单个任务设计的模型。我们已经证明了这一点,因式分解机可以模仿许多最成功的分解模型(包括MF,PARAFAC,SVD++,PITF,FPMC)只需通过特征提取即可,这使得FM在实践中很容易应用。
6、结论
在这片论文中,我们介绍了因式分解机。FMs融合了SVM模型的泛化能力以及因式分解模型的优势。不同于SVM模型,1)FMs可以在高稀疏的情况下进行参数估计,2)模型等式是线性的并且仅依赖于模型的参数,因此3)它们可以在原始等式中进行优化。FMs模型的解释力相当于多项式SVMs模型。不同于像PARAFAC这种张量因子分解模型,FMs是一个泛化的模型,它可以处理任何实值向量。再者,可以通过在输入特征向量中使用正确的表征来进行简化,FMs相对于其他特别高级的模型来说是更单一且非常简单的,不像那些模型仅仅只能应用在特定的任务重,例如MF, SVD++, PITF和FPMC。
参考博文:点击率预测《Factorization Machines》论文精读-ronghuaiyang