
原始论文:The Learning Behind Gmail Priority Inbox
Gmail优先收件箱背后的学习
摘要
Gmail的优先收件箱功能是按用户会对邮件进行操作新行为的概率来对邮件进行排名的。因为“重要性”非常个性化的,我们尝试通过学习每个用户统计模型来预测它,并尽可能的频繁地更新模型。本研究报告描述了在线学习的挑战通过数百万个模型,以及采用的解决方案。
1 Gmail的优先收件箱
许多Gmail用户每天都会收到数十或数百封邮件。优先收件箱试图缓解这种信息过载,主要通过学习每个用户的重要性统计模型和基于用户对该邮件采取行动的可能性对邮件进行排名来做到。这不是一个新问题[3,4],但为了要规模性的做到这一点,需要每天对数百万个模型进行实时排名和近线在线更新会使问题复杂化。这种挑战包括在明确的用户标签的情况下来推断没有邮件的重要性;找到处理非静止和含有噪声的训练数据;构建减少培训数据要求的模型;存储和处理每个用户太字节的特征数据;最后,以分布式和容错的方式进行预测。
虽然从Gmail垃圾邮件检测从机器学习的应用中借鉴了想法[6],但由于用户对什么是重要事项持不同意见,这是需要高度个性化的,因此重要性排名更难。结果这成为了ML在Google上面临的最大且面向用户的应用程序之一。
2 学习问题
2.1 特征
几个类别的特征却包含了成千上百的具体特征。社会特征是基于发送者和接收者之间交互的程度,例如发件人邮件的被收件人阅读的百分比。内容特征尝试识别与收件人在邮件上行为(或无行为)高度相关的标题和最近的术语,例如在该主题中存在最近的术语。在学习之前的预处理步骤中发现了最近的用户术语。路线特征会记录用户的到目前为止与路线的交互,例如,如果用户开始一个帖子。标签功能检查用户用来筛选邮件的标签。我们在排名期间计算特征值,并且我们暂时存储这些值以供以后学习。连续型特征会自动分区为二值特征,通过在特征值的直方图上使用简单的ID3样式算法来实现。
2.2 重要性矩阵
优先收件箱的目标就是在没有确切用户标签的条件下进行邮件排序,并且要允许系统达到“开箱即用”的工作效果。真正实地的重要性是基于在邮件发送后用户和其之间的互动。我们的目标是预测在邮件发送后的T秒内用户与邮件产生互动的概率,然后按照此进行邮件排序,我们预测的概率$p=Pr(a\in A,t \in (T_{min},T_{max})|f,s)$;这里的a是在邮件上的行为,A是贡献重要性的行为集合(例如打开,回复,手动修正),t是邮件发送后和产生行为之间的时间间隔,f是特征的向量,s表示用户有机会能够看到邮件。
要注意的是$T_{min}$是给用户有机会对新邮件进行操作的必要时间,但是这也收到我们能够多频繁地更新模型的限制。但肯定是小于24小时的。还要注意的是$T_{max}$限定了我们需要考虑进行存储和处理成邮件特征的可得到的资源数据。这是按天进行测算的。一个结论是大于$T_{max}$的时间区间中的用户行为是不会进入训练数据的。总结一下,预测误差是:
2.3 模型
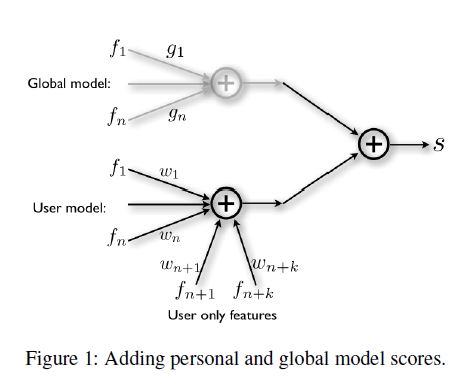
我们用简单的线性逻辑回归模型来进行规模性的学习和预测。我们有大量的数据可以用来训练一个全局的模型,但是对于具体到单个用户的个性化模型来说就没有充足的数据来进行学习了。我们用一个简单的形式来转换学习方式,那就是将全局模型和用户个性化模型的对数概率和作为最终的预测值。
特征的个数用n来表示,我们用了k个没有出现在全局模型中的用户个体特征。全局模型的权重系数g是互相独立地进行更新的,并且当个性化模型更新时其是固定的。因此,个性化模型的权重系数w仅仅代表了这个用户相对于全局模型是有多么的不同。这样的结果使得个性化模型变得更加简洁,因为在有新的特征加入的时候其可以快速地在全局模型的基础上进行迭代。
在线被动积极性更新[2]的时候,我们使用PA-II回归变体执行来对抗训练集中的高度噪音。每个邮件仅用于更新一次全局模型和更新一次邮件收件人的模型,例如第i个用户模型权重的更新是
其中e是误差,C是正则化参数,用于调整更新的“激进性”,并且$\epsilon$是铰链损失容差,或“被动”的程度。在实践中,我们通过控制C来调整每封邮件代表我们对标签的信任度,例如用户的手动校正会给出更高的值C.用户模型的C值也高于全局模型,新用户模型的C值更高仍然是为了促进初始学习。
2.4 分类排序
我们确定s的每个用户阈值,以将每个邮件分类为重要或不重要。我们把这个问题当成排名而不是分类,因为快速调整阈值对于用户感知的表现是至关重要的。想要通过算法方式设定一个阈值从而使得每个用户都有效是很困难的。打开邮件是我们的重要性矩阵中很强烈的信号(第2.2节),但很多用户会打开特别多的邮件这就说明他们只是“感兴趣”而不是表名这个邮件对他们“很重要”。此外,与垃圾邮件分类不同,用户不同意假阳性与假阴性的成本。我们的经验显示了巨大的用户对重要邮件量的偏好之间的差异,这些偏好无法与他们的行为相关联。因此,我们需要用户进行一些手动干预来调整其阈值。当一个用户以一致的方向标记消息,我们对他们的阈值执行一个实时增量。
3 产品
将学习扩展到数百万用户与为单个用户调整算法一样困难。储藏和服务模型,以及收集邮件训练数据,我们广泛使用大数据表[1],其中将分布式文件系统的功能与数据库相结合。
3.1 预测时间
优先收件箱以远远超过单台计算机容量的速率对邮件进行排名。要通过处理用户的Gmail帐户的数据中心来预测是很困难的,因此我们必须能够对来自任何数据中心的用户进行打分,且不会延迟邮件传递。大数表用于全局复制并为专门的排名任务来服务模型。特征提取和打分后,另一个大数表用来记录那些用于学习的特征。
通过维护每个用户的记录:message-id,将数据记录到大数表可以实现邮件功能与后续用户操作的实时合并。因此,模型更新所需的所有数据都是位于同一记录中。如果我们要将所有功能和操作附加到磁盘上的文件中,当它们发生的时候,那就需要数百台机器花费数小时进行聚合和排序用户日志。大数表在许多应用程序中共享这些资源并提供实时记录合并,使数据在全球范围内可用,以便在几分钟内完成学习。
3.2 学习
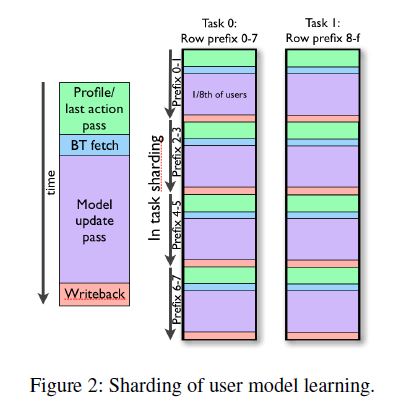
分片学习在概念上很简单。每个核心负责更新一小部分用户模型。面临的挑战是以保持核心繁忙的速度通过网络提供数据。 大数表通过提供对已排序用户:message-id记录的全局访问来完成大量此工作。简单地获取用户模型,为每个消息记录执行更新,然后回写模型是很诱人的。不幸的是,有数百万用户通过网络对单个模型读写的被惩罚为禁止的。有必要进行批量用户模型读写,将许多模型尽可能加载进入RAM。为了提高效率,大数表以近似方式执行批量读取密钥顺序,允许跨持有数据的服务器的并行性。由于消息是由user:message-id键控的,消息可能偶尔不在用户订单中。
为了评估我们的隐式指标,我们需要知道用户上次在Gmail中处于活动状态。我们不能够确定这一点,直到所有user:message-id记录都被读取,因为它们不是暂时的订阅。这需要两次通过大数表中保存电子邮件数据的每个用户模型的分片。其中第一次通过是计算用户分片上的最后一个动作时间和其他统计信息。大部分需要传输的数据很小,因此第一次传递很快。第二遍扫描所有消息特征数据,执行更新。最后,所有已更改的用户模型都是批量写回到大数表的。因此,每个可用核心按用户ID前缀和该分数给予一小部分用户进一步划分为用户分片,其中所有模型可以同时保存在RAM中(图2)。最终结果是,在非高峰非专用类似桌面机器的条件下,我们可以在每个核心每秒处理35个用户。一些用户有数千个更新,有些用户有一个。这是一个重要的通过24/7专用任务实现真正在线学习的资源节约。
3.3 数据保护
所有的用户数据均在谷歌隐私政策条件下进行分析和存储,从消息中提取出的特征数据在训练后就会被删除。为了调试和优化,团队成员仅仅会用他们自己的账户进行特征和统计模型的测试。
4 结果
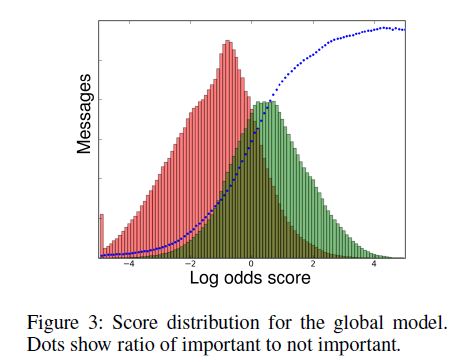
图3展示了一个经典的全局模型的对数概率分的柱状图,其中绿色的表示重要的消息,红色的则表示不重要的。这表示了逻辑回归具有多少的平滑排序功能。每个桶底包含了一个根据对数概率曲线从重要到不重要的比例。
基于我们隐含的重要性定义,相比于对照组我们的准确度$(tp+tn)/message$接近于$80\pm5\%$。显示偏差导致活跃的优先性收件箱用户的准确度提高2或3%。这个数字比看上去要好。由于阈值调整,我们的假阴性率是假阳性率的3到4倍。用户阅读他们承认并不重要的邮件,因此很多我们的错误否定从用户的角度却应该是正确分类。这说明了确定隐含重要性的困难,数据集中的噪声水平以及评估用户感知质量的挑战。来自用户的手动标记是有价值的,因为它们提供了重要性的真实评估,尽管它们主要来自分类错误并因此具有偏差。从一组160k这样的标记我们计算出仅应用全局的模型与个性化模型和嘉善够个性化阈值的个性化模型间的区别(表1)。趋势是增加个性化可以显着减少错误。
最终目标是帮助Gmail用户。我们分析了有和没有优先收件箱的条件下Google员工在电子邮件上花费的时间。对收到类似邮件量的Google员工进行取平均值,优先收件箱用户(约2000名用户)整体阅读邮件的时间减少了6%,阅读不重要的邮件时间减少了13%。他们也更有信心批量存档或删除电子邮件。
| Combination | Error |
|---|---|
| Global model | 45% |
| User models | 38% |
| User models & thresholds | 31% |
Table 1: Error rates on user marked mail